Most organizations recognize that data is an asset, yet few fully monetize or even mobilize it. In fact, the majority of business leaders overestimate how much of their information assets are truly ready to be leveraged. At HudsonLogic, we believe this gap is the heart of the Data Readiness → AI Readiness journey: without trusted, curated, and accessible data, AI initiatives will underperform.
Alternative Data as a Readiness Accelerator
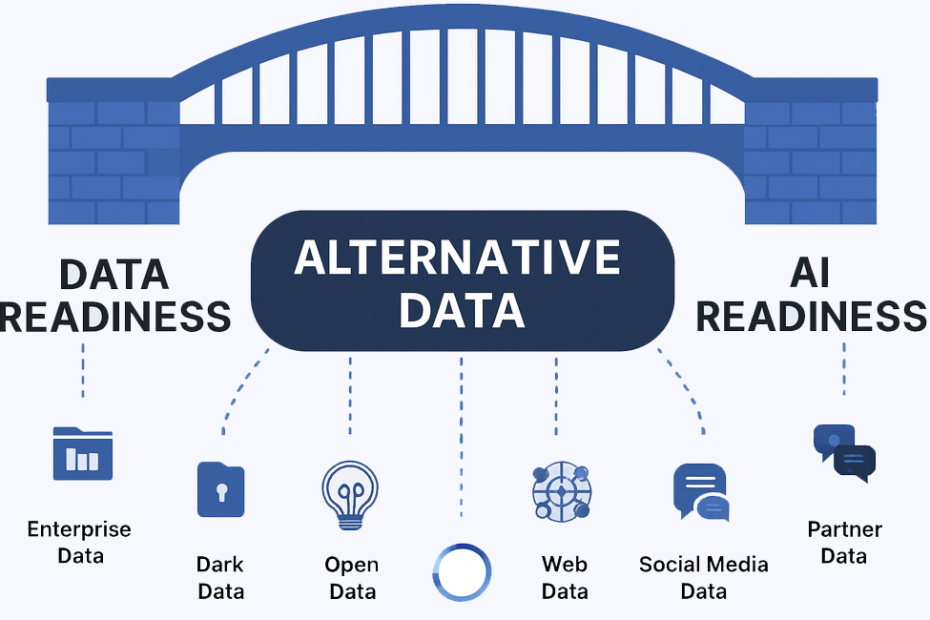
The most valuable insights rarely come from your owned systems alone. AI thrives on variety, scale, and context—making alternative data sources an essential catalyst. When combined with enterprise data, these external inputs create the breadth and depth required for training machine learning models, feeding decision intelligence, and powering predictive analytics.
The Seven Sources of Data for AI Readiness
- Enterprise Data – The foundation: CRM, ERP, HR, and supply chain data. Reliable but often siloed.
- Dark Data – Archived emails, logs, and documents. Unlocking this improves training data coverage.
- Open Data – Government and public datasets add macroeconomic and demographic context.
- Web Data – Competitor and market signals scraped from digital channels enrich AI-driven forecasting.
- Social Media Data – Sentiment and behavior insights help fine-tune customer and brand AI models.
- Partner Data – Collaboration and second-party data sharpen supply chain AI use cases.
- Syndicated Data – Purchased datasets extend predictive capabilities (e.g., financial, weather, market).
AI models are only as strong as the diversity, quality, and governance of the data they consume. Integrating across these seven categories pushes your organization beyond basic data readiness toward true AI readiness.
Data Curation: The Readiness Discipline Most Organizations Lack
You wouldn’t leave critical supply chains unmanaged—yet most organizations have no equivalent discipline for sourcing and curating external data. Establishing a data procurement and curation function is critical for:
- Assessing data quality and reliability (to avoid poisoning AI models).
- Evaluating cost vs. business value of each new source.
- Ensuring compliance with sovereignty, privacy, and ethical standards.
This isn’t just operational hygiene. It’s the foundation for building trustworthy AI pipelines.
From Data Readiness to AI Readiness
HudsonLogic frames readiness as a progression:
- Data Readiness ensures your data is complete, governed, and available.
- AI Readiness extends this by ensuring your data is diverse, contextual, and machine-usable.
Alternative data sources are the bridge. They make your datasets broader, richer, and more representative, enabling:
- Better-trained models with fewer biases.
- More accurate predictions across industries (e.g., supply chain, finance, energy).
- Faster experimentation cycles for new AI use cases.
Recommendations for Forward-Thinking Organizations
To stay competitive in the AI era, organizations should:
- Implement a data procurement & curation function as a core discipline.
- Develop a data sourcing roadmap aligned to high-value AI use cases.
- Invest in platforms and governance that standardize and harmonize disparate sources.
- Continuously measure both data value and AI outcome impact.
👉 At HudsonLogic, we help organizations move from data chaos to data readiness, and from data readiness to AI readiness. By curating and activating alternative data sources, we enable businesses to accelerate AI adoption with confidence, precision, and trust.